
エクセル連携例(主成分分析)
代表的な表計算ソフト、マイクロソフト社のエクセル(Excel)と C# (そして Mol)との連携について若干の例を作成しました(プログラムは例題に組み込まれていますので、ダウンロードして実行してみてください)。
Mol はエクセル等では扱うことが困難な程の大規模計算を C# 等から簡単に扱えるようにしたものです。とはいえ、計算結果の整理や結果の表示・印刷にエクセルは
非常に便利です。例題では、既存のエクセルファイルを指定して(必要なら新規にエクセルを起動します)、そのセル領域と Mol のベクトルや行列データを
やり取りします。
※VBAやマクロでエクセルは大幅な機能追加、処理の自動化を実現できます。しかし、VBAやマクロを含むエクセルファイルは
ウィルスに感染しているとみなされる場合があります。また、VBAやマクロはファイル単位で保存されるため、同じVBAやマクロを含むファイルが複数ある場合は修正が面倒になります。
従って、本例のようにVBAやマクロと同等(以上)の機能をエクセルファイルの外側で用意(操作)することは意味のあることです。
エクセルの準備
以下、エクセルは正常にインストールされているものと仮定します。
(エクセル(Office)によってはインストール時に「.NET プログラミングのサポート」というチェックボックスがある場合、必ずチェックしてください。)
次に、Visual Studio を起動して、[参照の追加]ウィンドウを表示、[COM]タブを選択し、「Microsoft Excel xx Object Library」を選択します。
ここで、xx はインストールされているエクセル(オブジェクト)のバージョン番号になります。
最終的に、ソリューション・エクスプローラの「参照設定」のツリーに「Microsoft.Office.Core」と「Microsoft.Office.Interop.Excel」が表示されればプログラミング準備完了です。
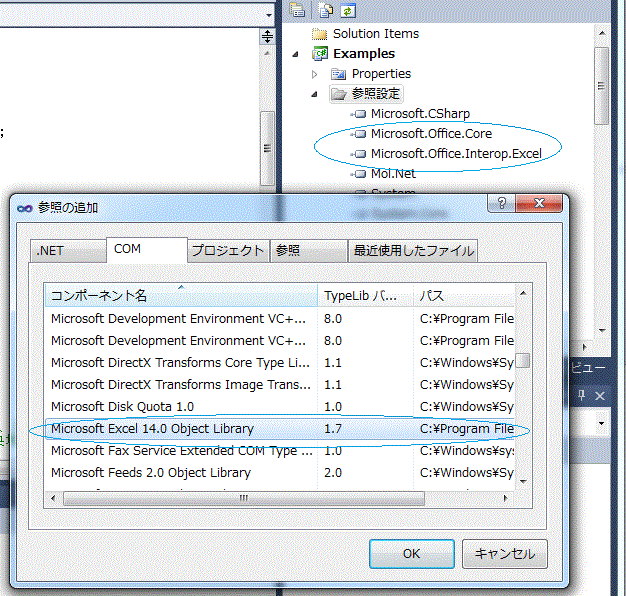 例題では既に Microsoft Excel 2010 への参照(Microsoft Excel 14.0 Object Library)が追加されています。
もし、インストールされているエクセルのバージョンが異なるとき(でコンパイルや実行時に問題が発生する場合)には一旦参照を削除してから再度追加してください。エクセルのバージョンが少々異なってもプログラムコードは共通に使用可能のはずです。
例題では既に Microsoft Excel 2010 への参照(Microsoft Excel 14.0 Object Library)が追加されています。
もし、インストールされているエクセルのバージョンが異なるとき(でコンパイルや実行時に問題が発生する場合)には一旦参照を削除してから再度追加してください。エクセルのバージョンが少々異なってもプログラムコードは共通に使用可能のはずです。
ExcelTool クラス
エクセルのワークブック、ワークシート、セル等にアクセスする C# コードは例題の excel.cs (ExcelToolクラス)にまとめて記述されていますので
詳細はソースコードを参照してください。
最初に ExcelTool クラスのインスタンスを作成します(引数に既存のエクセルファイルのパスを指定します)。
ExcelTool excel_tool = new ExcelTool("c:\\test\\sample.xlsx");
次に、指定したエクセルファイルの Workbook オブジェクトを取得します。
Workbook wb = excel_tool.Book;
この時点で、既に起動中で、コンストラクターで指定したエクセルファイル("c:\\test\\sample.xlsx") をオープンしているエクセルがあれば、
そのエクセルに接続して対応する Workbook オブジェクトを取得します。そうでなければ新しくエクセルを起動後、指定したエクセルファイルを
オープンしてその Workbook オブジェクトを取得します。従って、Workbook オブジェクトが必要なときは必ず、上記のように Book プロパティを
利用してください。
さらに、ブックに含まれる Sheet オブジェクトを取得します(以下は Excel Object の使用方法の解説ですので、詳細は関連するドキュメントを参照してください)。
Worksheet ws = (Worksheet)wb.Sheets["Sheet1"];
Mol のベクトルや行列データをシート(ws)から読み込んだり、シートに書き込むにはシート上の位置(Range オブジェクト)を
取得して ExcelTool の LoadVector()/SaveVector() や LoadMatrix()/SaveMatrix() メソッドに渡します。
// エクセルのセル "L4" からベクトル V1 を右横、"L8" から行列 M1 を右下、に向けて書き込みます。
excel_tool.SaveVector(V1, ws.Range["L4"], true);
excel_tool.SaveMatrix(M1, ws.Range["L8"]);
例題(主成分分析)解説
まず、Mol 例題をダウンロードして、実行してみてください。
実行手順は以下のようになります。
- MolExample32.exe か MolExample64.exe を実行すると、以下の図のように、各種テスト機能のボタンダイアログが表示されます。
- 「EXCEL」ボタンをクリックすると「データ読込み」と「計算」ボタンのみの小さなダイアログが表示されます。
- 「データ読込み」ボタンをクリックするとエクセルシート上の「分析対象成績データ」領域のデータを行列に読み込みます。
- 「計算」ボタンをクリックすると各種基本統計量と主成分(第1、第2)がエクセルシートに書き込まれます。
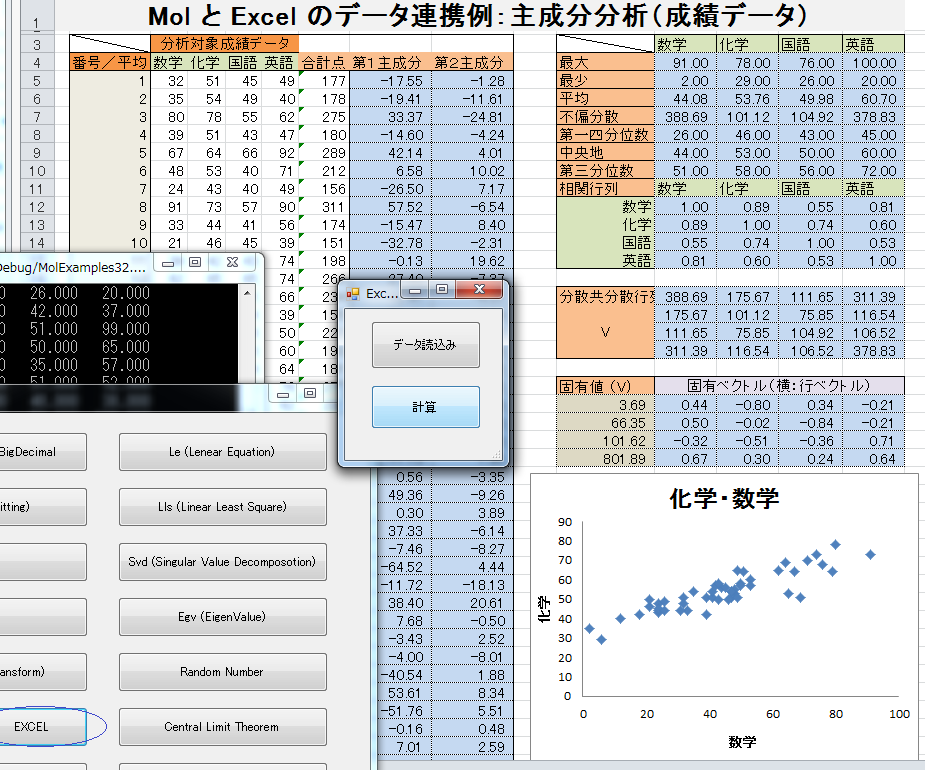
Molの基本統計(Stat)と固有値分解(EgvSolver)クラスによる主成分分析解説
例題のエクセルシートには50人の数学(x1)、化学(x2)、国語(x3)、そして英語(x4)の
試験結果(入試問題の得点とでもします)が記入されています。
この得点から合否を判定するには、単純な得点合計 s = x1 + x2 + x3 + x4 を利用するのが
一般的です。しかし、当然ながら各科目の難易度を同程度にするのは難しく、得点のばらつき(分散)は科目ごとに異なります。
従って、本来なら各科目の得点に難易度に応じた重みを付けた合計点で判定するほうが公平ではないかという考えも成り立ちます。
合否の判定は極端にしても、入試問題結果の傾向を知るという意味はあります。
主成分分析の詳細は参考書等に譲るとして、ここでは簡単に説明します。
たとえば、数学と化学の散布図をみると両科目には明らかに正の相関があります。
そこで、まず、
座標原点を各科目の重心(平均)に移動し、変位 xi(=データ値 - データの平均値、i=1,…,4)を処理の対象に考えます。
そして、4種の重み付き指標を新たに導入します(同じ x を用いますが、以下の x は平均からの変位を意味します)。
y1 = x1e11 + x2e12 + x3e13 + x4e14
y2 = x1e21 + x2e22 + x3e23 + x4e24
y3 = x1e31 + x2e32 + x3e33 + x4e34
y4 = x1e41 + x2e42 + x3e43 + x4e44
この eij をうまく設定することでデータ全体の見通しをよくする(yi同士の関連性・相関を無くす)というのが主成分分析の第一ステップです。
まず、添え字を簡単にするために列ベクトル ei = [e1i,e2i,e3i,e4i]T を導入して
y = x1e1 + x2e2 + x3e3 + x4e4
ei は列ベクトルなので、行列 E = (e1,e2,e3,e4) として、データ行列 X は変換により、新しい
データ行列 Y に Y = XE と変換されます。
ei に正規直交単位ベクトル(ei・ei=1、ei・ej=0 i≠j、よって E は直交行列)を選択して(各変数の平均値を原点とした)重心を中心に回転することを考えます。
では、どのように回転するのかが問題になりますが、得点データの分散・共分散行列(V)の固有値分解と結びつけることができます(相関行列を使用することも考えられます)。
すなわち
Vei = λiei (i=1,…,4)
とする固有ベクトル ei を新たな座標軸(の基底単位)とします。
行列 V に E を掛けることで V が対角化(直交ベクトル e は固有ベクトルなので E-1VE = λ、λ は対角行列でλiが対角成分)されることに注意してください。対角要素以外がゼロなので、新たな y 同士は無相関になります。
また固有値の性質から x の分散の和(Vの対角要素の和)と y の分散の和(固有値の和)は同じ値になります(回転だけなので原点からのばらつき全体は変化しません)。
この固有値(4つ)の最大値(yの分散の最大値)に対応する固有ベクトルに対応する y の値を第一主成分、次の値に対応する値を第二主成分…と言います。
V は対称行列で対角成分(分散)は必ず正の値ですので、固有値の性質から、V は正定値行列です。
データ行列(各要素は平均からの変位に変換したもの)を X とすれば、X の分散共分散行列 V は V = XTX と表現(自由度で除する部分などは無視)されます。
Y = XE の分散共分散行列 Vy は Vy=YTY = ETXTXE = E-1VE =>λ、 Vy を対角行列 λ に変換することは V の固有値問題(VE=Eλ)に帰着されます。
固有値(λ の対角要素)の値が極端に異なる場合、固有値の大きい主成分だけである種の判断情報を得るのが主成分分析の目的になります。
例題では基本統計量の計算は Mol の Statクラス、固有値分解には EgvSolver クラスを使用しています(もちろん、エクセルにも同様な機能は備わっています)。
以下、例題より抜粋
// データ行列
MatrixDenseGeneralDouble Mat = new MatrixDenseGeneralDouble(50, 4);
// m_bookTool は ExcelTool オブジェクト、m_stat は Stat オブジェクト
m_bookTool = new ExcelTool(m_xlsFile);
m_stat = new Stat(Mat);
VectorDenseDouble QuantileOrder = new VectorDenseDouble(3); // 分位率
// j 番目の(列)データ平均値は m_stat.Mean[j] という形で得られますが中央地は、以下のように m_stat.QuantileOrder に
// 0.5 を指定した部分(i=2) に格納されます。従って、 j 番目の(列)データの中央地は m_stat.QuantileMatrix[2,j] になります。
QuantileOrder[1] = 0.25;
QuantileOrder[2] = 0.5; // 中央地
QuantileOrder[3] = 0.75;
m_stat.QuantileOrder = QuantileOrder;
m_stat.Computed = Stat.PROPERTIES.ALL;
// m_xlsFile をオープンしているエクセルに連結します(存在しなければエクセルを起動)
Workbook wb = m_bookTool.Book;
Worksheet ws = (Excel.Worksheet)wb.Sheets[m_sheetName];
// シートからデータ行列を Mat に読み込む
m_bookTool.LoadMatrix(Mat, ws.Range["C5"]);
// シートから読み込んだデータから基本統計量を計算
m_stat.ComputeProperties();
// 基本統計量をエクセルシートに書き込む
m_bookTool.SaveVector(m_stat.Max, ws.Range["L4"], true);
m_bookTool.SaveVector(m_stat.Min, ws.Range["L5"], true);
m_bookTool.SaveVector(m_stat.Mean, ws.Range["L6"], true);
m_bookTool.SaveVector(m_stat.Variance, ws.Range["L7"], true);
m_bookTool.SaveMatrix(m_stat.QuantileMatrix, ws.Range["L8"]);
m_bookTool.SaveMatrix(m_stat.CorrelationMatrix, ws.Range["L12"]);
m_bookTool.SaveMatrix(m_stat.CovarianceMatrix, ws.Range["L17"]);
// 固有値分解
MatrixDenseSymmetricDouble A = (MatrixDenseSymmetricDouble)m_stat.CovarianceMatrix.Clone();
EgvSolver es = EgvSolver.Solve(null,null,A);
m_bookTool.SaveVector((VectorDenseDouble)es.EigenValues, ws.Range["K23"], false);
m_bookTool.SaveMatrix((_MatrixDouble)_Matrix.Transpose(null, (_MatrixDouble)es.EigenVectors), ws.Range["L23"]);
// 第一主成分
MatrixDenseGeneralDouble vecs = (MatrixDenseGeneralDouble)es.EigenVectors;
VectorDenseDouble mean = m_stat.Mean;
// 主成分ベクトル
VectorDenseDouble C = new VectorDenseDouble(Mat.RowCount);
// 第一主成分をエクセルシートに書き込む(Matはデータ行列)。
for (int i = 1; i <= Mat.RowCount; ++i)
{
double s = 0;
for(int j=1;j<=Mat.ColumnCount;++j)
{
s += vecs[j,4] * (Mat[i, j] - mean[j]);
}
C[i] = s;
}
m_bookTool.SaveVector(C, ws.Range["H5"], false);
// 第二主成分をエクセルシートに書き込む。
for (int i = 1; i <= Mat.RowCount; ++i)
{
double s = 0;
for (int j = 1; j <= Mat.ColumnCount; ++j)
{
s += vecs[j, 3] * (Mat[i, j] - mean[j]);
}
C[i] = s;
}
m_bookTool.SaveVector(C, ws.Range["I5"], false);
※固有値分解の性質として固有ベクトルの符号は一意に定まらないので、単純に主成分の大小で判断することは間違いのもとになります。
※統計的には主成分の値を考慮して合否を判断するのが公平かもしれませんが、それが受験生に受け入れられるかどうかは別の話です。
